# install.packages("tidyverse")Introducción a dplyr
Nociones básicas de las funciones
R
tidyverse
dplyr
programación
Nota. Para cualquier consulta, sugerencia o corrección de errores en el cuerpo del texto, por favor, póngase en contacto a través del siguiente correo electrónico: IVAN.RODRIGUEZCRUZ@ucr.ac.cr
Introducción
El tidyverse de Wickham et al. (2019) es un conjunto de paquetes de código abierto para el lenguaje de programación R que ha ganado gran popularidad en la comunidad de ciencia de datos y estadística debido a su enfoque coherente y consistente en el manejo de datos. Estos paquetes fueron desarrollados con el objetivo de proporcionar una herramienta poderosa y eficiente para la manipulación, limpieza, visualización y análisis de datos en R.

dplyr. Ilustración de Allison Horst.El pilar central del tidyverse es el paquete dplyr, que ofrece un conjunto de funciones simples y concisas para realizar operaciones fundamentales en la manipulación de datos, como filtrar, seleccionar, ordenar, agrupar y combinar datasets. Junto con dplyr, otros paquetes importantes del tidyverse incluyen tidyr Wickham, Vaughan, y Girlich (2023), que se utiliza para transformar y reorganizar datos en formatos tidy (ordenados); ggplot2 Wickham (2016), una potente librería para crear gráficos elegantes y expresivos; readr Wickham, Hester, y Bryan (2023), que facilita la lectura y escritura de datos en R en diversos formatos; y lubridate Grolemund y Wickham (2011), que facilita el manejo de fechas y horas de formas más eficiente.
En este documento, busca presentar y explicar de manera detallada y amigable las funciones más esenciales de dplyr, brindando ejemplos prácticos dirigidos específicamente a los estudiantes de la carrera de Estadística de la Universidad de Costa Rica. Con el dominio de este paquete del tidyverse, los aprendientes podrán potenciar sus habilidades en el análisis y visualización de datos, simplificando la preparación en ciencia de datos y estadística para proyectos de investigación en diversos cursos de la malla curricular.
De esta forma, dplyr con su enfoque intuitivo, claro y coherente, se convierte en una herramienta imprescindible para aquellos que buscan un flujo de trabajo eficiente y robusto en R para la manipulación datos.
Asimismo, al final de este documento se encuentra el Cheatsheet de dplyr que contiene todas aquellas funciones más esenciales que lo componen.
Nociones de dplyr
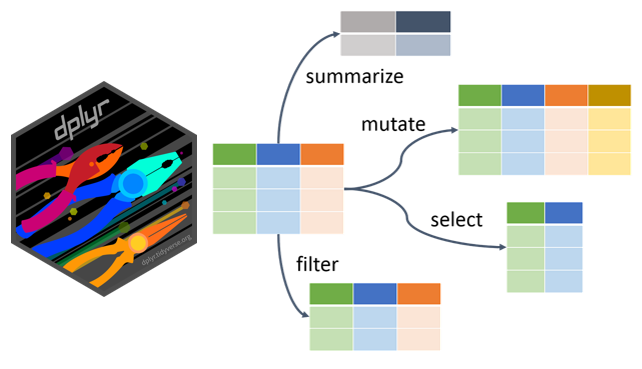
dplyr.Requisitos básicos
¿Qué es dplyr y para qué sirve?
La librería dplyr es una poderosa herramienta en R utilizada para el manejo eficiente de datos, permitiendo filtrar, agrupar, resumir y manipular datasets de manera intuitiva. Su sintaxis simple facilita el análisis exploratorio y la preparación de datos para su posterior visualización y modelado estadístico. Con funciones como filter(), select(), mutate(), summarise(), y arrange(), dplyr se ha convertido en una opción esencial para científicos de datos y analistas que desean optimizar su flujo de trabajo y obtener resultados precisos de forma rápida.
Por ende, para adrentrase en las funciones de este paquete, es fundamental comprender que él se integra dentro del tidyverse. Al cargar dicho paquete en el entorno de R, se dispone de todas las herramientas necesarias para realizar una manipulación eficiente de los datos.
Instalar tidyverse
Para poder gozar de todos las librerías mencionadas más arriba, es necesario instalar y cargar la librería de tidyverse. Una vez completado estos pasos ya será posible hacer uso de las funciones del paquete de dplyr.
De esta forma, primero se debe instalar tidyverse y luego cargar su librería al entorno de R.
library(tidyverse)Base de datos
Para ejemplificar cada una de las funciones que se trabajarán en este manual, se utilizará la base de datos penguins de Horst, Hill, y Gorman (2020) de la librería palmerpenguins en R. Esta base de datos proporciona información detallada sobre tres especies de pingüinos (Gentoo, Adélie y Chinstrap), incluyendo medidas físicas, sexo y peso.
![]()
palmerpenguins de Allison Marie Horst, Alison Presmanes Hill y Kristen B Gorman.Instalación de la base de datos
# Instalar el paquete que posee la base de datos:
# install.packages("palmerpenguins")library(palmerpenguins)Una vez instalado y cargado la librería de palmerpenguins de Horst, Hill, y Gorman (2020), entonces, la base de datos en cuestión es la siguiente:
# Visualizar la base cargada:
penguins %>% head Simplicidad con el Pipe %>%
El operador %>% del paquete magrittr de Bache y Wickham (2022) es un poderoso operador de tuberías (conexión) que permite encadenar múltiples funciones de manera legible y concisa. Con su sintaxis intuitiva, facilita la manipulación y transformación de datos, mejorando la legibilidad del código y evitando anidaciones excesivas. Es una herramienta fundamental para la programación funcional en R y favorece un flujo de trabajo más eficiente en análisis y manipulación de datos.
![]()
magrittr donde se encuenta el operador Pipe %>%.La estructura básica de este operador se puede entender de la siguiente manera
base %>% function_1() %>% ... %>% function_n()El operador pipe %>% permite encadenar funciones de manera más legible y estructurada, lo que facilita el procesamiento de datos. A continuación, se presenta un ejemplo que ilustra la diferencia entre usar el operador pipe y no utilizarlo:
# Sin utilizar el pipe:
summarise(group_by(penguins, species), total = n())# Utilizando el pipe:
penguins %>%
group_by(species) %>%
summarise(
total = n()
)De esta forma, el operador pipe %>% destaca por su flexibilidad y facilidad de lectura en el código. Su uso se recomienda ampliamente debido a la claridad con la que se pueden encadenar múltiples funciones. Para explorar en detalle todas las ventajas y posibilidades que ofrece este operador, se puede consultar el siguiente enlace: https://magrittr.tidyverse.org/reference/pipe.html
Operadores de comparación y lógicos
Antes de iniciar con desglosar las principales funciones de la librería dplyr es necesario saber que, para aprovechar funciones como filter() de manera efectiva, es crucial comprender cómo seleccionar las observaciones deseadas mediante el uso de operadores de comparación. En R, se dispone de un conjunto estándar de estos operadores:
| Operador | Comando | Operador | Comando |
|---|---|---|---|
| Igual | = |
Menor estricto | < |
| Diferente | != |
Mayor igual que | >= |
| Mayor estricto | > |
Menor igual que | <= |
También, es necesario tener presente los operadores lógicos que son de suma importancia para aspectos de filtrado del marco de datos. Los principales operadores lógicos que contiene R son:
| Operador | Comando |
|---|---|
| “And” \((\wedge)\) | | o también & |
| “Or” \((\vee)\) | || |
| “Not” | ! |
Funciones básicas de dplyr
Filtrar filas: filter()
La función filter() permite obtener un subconjunto de observaciones basado en los datos de un dataset. El primer argumento es el nombre del marco de datos. Los argumentos siguientes son las expresiones que filtran el marco de datos. La estructura base sería la siguiente:
base %>% filter(variable_1, variable_2, …)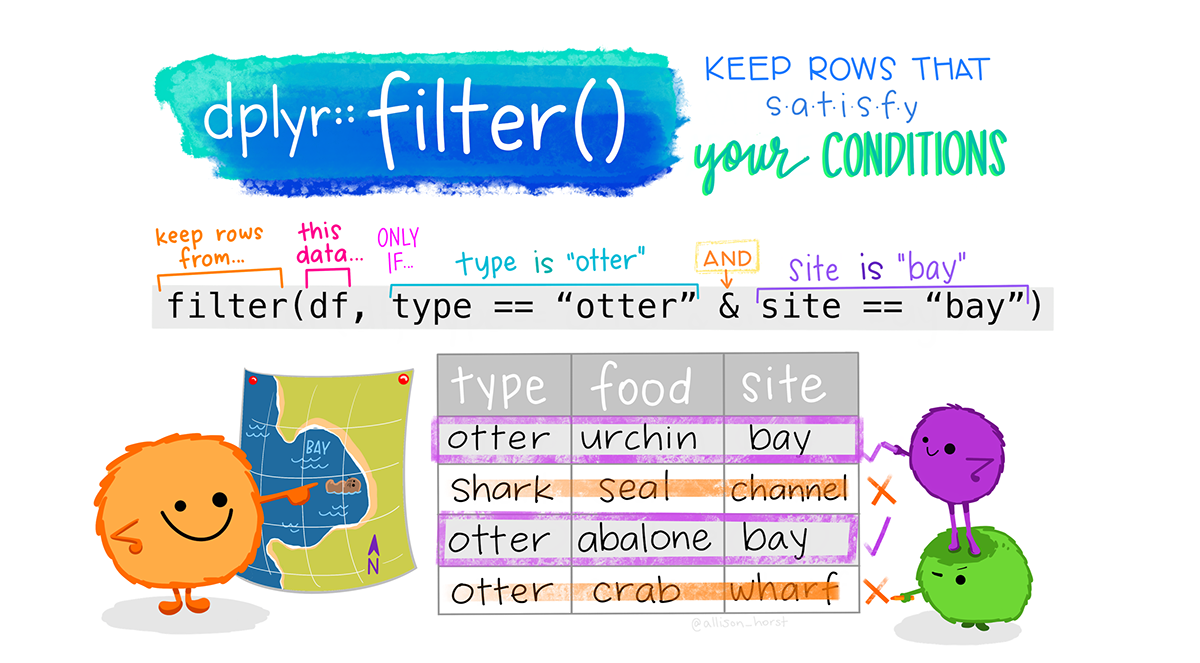
filter(). Ilustración de Allison Horst.Ejemplos
De esta manera, es importante tener en cuenta que es posible aplicar filtros a la base de datos, por ejemplo, para seleccionar pingüinos de la isla Dream, de género femenino y con una longitud de pico menor o igual a 40.5 cm.1
1 De aquí en adelante se va a usar la función head() para presentar únicamente los primeros seis datos de cada base de datos.
penguins %>%
filter(island == "Dream",
sex == "female",
bill_length_mm <= 40.5) %>%
head()Además, dentro de esta función también se pueden emplear operadores lógicos. Por ejemplo, es factible seleccionar únicamente aquellos pingüinos que hayan sido analizados en el año 2007 o en el 2009.
penguins %>%
filter(year == 2007 | year == 2009) %>%
head()Un ejemplo adicional sería filtrar pingüinos de especies diferentes a Adélie, y cuya longitud de aleta esté entre 185 mm y 197 mm.2
2 El comando para elegir valores en un rango en concreto corresponde a: x %in% y. Véase el siguiente enlace que contiene más información al respecto de los uso de este operador: https://sparkbyexamples.com/r-programming/usage-of-in-operator-in-r/?expand_article=1
penguins %>%
filter(species != "Adelie",
flipper_length_mm %in% 185:197) %>%
head()Ejemplos extra
Algunos otros ejemplos se pueden consultar en el siguiente enlace: https://dplyr.tidyverse.org/reference/filter.html
Ordenar filas: arrange()
El objetivo principal de la función arrange() corresponde a ordenar las filas del marco de datos por una o varias variables en concreto; de forma predeterminada cuando se usa arrange() el marco queda ordenado de forma ascendente. En caso de querer ordenar los datos de forma descendente hay que utilizar la función desc(x), donde x es una variable.
La estructura base arrange() es la siguiente:
data %>% arrange(variable_1, ..., .by_group = FALSE)Ejemplos
A modo de ejemplo, la base de datos de pingüinos se ordenará de forma descendente según la variable bill_length_mm y de manera ascendente por la variable body_mass_g.
penguins %>%
arrange(desc(bill_length_mm), body_mass_g) %>%
head()Seleccionar columnas: select()
Es frecuente encontrarse con conjuntos de datos que contienen cientos o incluso miles de variables, y el desafío inicial suele ser enfocarse en las variables de interés. select() es una función que permite seleccionar rápidamente un subconjunto útil de columnas basándose en los nombres de las variables. Esto facilita el trabajo al elegir solo las columnas relevantes para el análisis o visualización, descartando las innecesarias.
Además, select() proporciona una amplia gama de funciones especiales para facilitar la selección de columnas. Algunas de estas funciones incluyen:
starts_with(): Selecciona columnas que comienzan con un prefijo específico.ends_with(): Selecciona columnas que terminan con un sufijo específico.contains(): Selecciona columnas que contienen una cadena específica en su nombre.matches(): Selecciona columnas cuyos nombres coinciden con una expresión en común.everything(): Selecciona todas las columnas de un marco de datos.
Ejemplos
Algunos ejemplos para entender el funcionamiento de la función select() y sus agregados, se pueden ver en las siguientes secciones.
select()
- Seleccionar las columnas relacionadas con la especie, isla y sexo.
penguins %>%
select(species, island, sex) %>%
head()Esta selección también pudo haberse realizado de la siguiente manera:
penguins %>%
select(-c(3:6,8)) %>% # También se puede poner los nombres de las variables.
head()starts_with()
Para seleccionar variables que comparten un prefijo en concreto se puede usar starts_with(). La forma correcta de emplear esta función con select() es la siguiente:
base %>% select(starts_with("..."))De esta forma, se van a elegir aquellas variables que empiecen por bill_:
penguins %>%
select(starts_with("bill_")) %>%
head()ends_with()
Para seleccionar variables que comparten un prefijo en concreto, se puede emplear starts_with() en combinación con select(). La forma correcta de utilizar esta expresión es la siguiente:
base %>% select(ends_with("..."))Un ejemplo concreto sería seleccionar únicamente aquellas variables que terminan con _mm y x:
penguins %>%
select(ends_with(c("_mm", "x"))) %>%
head()contains()
Para seleccionar variables que contienen una cadena específica, se puede utilizar contains() junto con select(). Su estructura corresponde a:
base %>% select(contains("..."))De la base de pingüinos se van a tomar en cuenta las variables que contienen en su nombre la cadena de caracteres th:
penguins %>%
select(contains("th")) %>%
head()matches()
En caso de tener que seleccionar variables que coinciden con un patrón regular específico, se puede usar matches(). La combinación de esta función con select() sigue la siguiente forma:
base %>% select(matches("..."))A modo de ejemplo, se seleccionarán las variables que coinciden con el patrón de *ength. El asterisco *, para este caso, omite los caracteres que están antes del patrón propuesto, lo que permite adaptar la selección según la posición del patrón en los nombres de las variables.
penguins %>%
select(matches("*ength")) %>%
head()everything()
Para seleccionar todas las columnas de un dataframe se puede utilizar everything en conjunto con select().3 Su estructura corresponde a:
3 Esta función no es tan común de utilizarla ya que, su propósito es lo mismo que tener el marco de datos completo desde un inicio.
base %>% select(everything("..."))Un ejemplo en concreto es el siguiente. Este devuelve toda la base de datos que se tenía desde un inicio del análsis.
penguins %>%
select(everything()) %>%
head()Crear o modificar variables: mutate()
Esta función se encarga de crear nuevas variables o transformar las existentes, basándose en operaciones matemáticas, funciones o combinando datos de diferentes columnas. mutate() es especialmente útil para realizar cálculos personalizados, como aplicar fórmulas, escalas o transformaciones a los datos.4
4 mutate() no altera el marco de datos original. Es decir, que permite conservar los datos originales mientras se generan nuevas variables derivadas, lo que evita problemas a futuro en los análisis respectivos.

mutate(). Ilustración de Allison Horst.La estructura base de mutate corresponde a
data %>% mutate(..., .by = NULL,...)Ejemplos
Para poner en contexto esta función, se creará una nueva variable que indique la diferencia (en mm) de la longitud de la aleta con un valor específico de 201 mm (media aproximada de la longitud de la aleta para todas las especies analizadas). También se creará una variable de identificación para cada pingüino.
penguins %>%
mutate(dif_aleta = round(mean(flipper_length_mm, na.rm = T),3) - flipper_length_mm) %>%
mutate(ID_ping = row_number()) %>%
select(ID_ping, flipper_length_mm, dif_aleta) %>%
head()Añadidos extra con mutate()
Dado que crear o modificar variables con mutate() ofrece diversas posibilidades, es común encontrarse con situaciones donde es necesario recodificar una variable (o varias), cambiar las etiquetas de una variable nominal (categórica), entre otros casos. Los siguientes ejemplos brindan una idea de cómo abordar estas situaciones, lo cual resulta útil en ejercicios prácticos de cursos de estadística.
Recodificar variables con condicionales: case_when()
Para realizar una condicional múltiple y crear una nueva variable basada en condiciones específicas, se puede emplear case_when() junto a mutate. La forma correcta de usar esta función es la siguiente:
base %>%
mutate(x = case_when(
condicion_1 ~ resultado_1,
...,
condicion_n ~ resultado_n
))Por ende, a modo de ejemplo genere una nueva variable a partir de body_mass_g donde se le asigne un 0 si es menor a la media general y un 1 si es mayor o igual que la media.5
5 Es posible usar la función ifelse() para generar esta recodificación. Sin embargo, la función case_when() es mucho más intuitiva y también forma parte de dplyr. También, es posible usar los operadores de comparación y lógicos mencionados más arriba.
# (Referencia) Media general del peso:
mean(penguins$body_mass_g, na.rm = T)[1] 4201.754penguins %>%
mutate(body_rec = case_when(
body_mass_g < mean(body_mass_g, na.rm = T) ~ 0,
body_mass_g >= mean(body_mass_g, na.rm = T) ~ 1
)) %>%
select(body_mass_g, body_rec) %>%
head(10)Cambiar la clase de una variable
En los casos en los que se necesite cambiar el tipo de una variable a otro (ya sea a numérico, factor, carácter, vector, etc.), se pueden utilizar las funciones as.. La estructura básica de estas funciones son las siguientes:
as.factor(x) ; as.numeric(x) ; as.vector(x) ; etc.Por ejemplo, para transformar las variables flipper_length_mm y body_mass_g a formato numérico y la variable year a formato factor, se puede realizar de la siguiente forma usando mutate():
penguins %>%
mutate_at(.vars = c("flipper_length_mm", "body_mass_g"), as.numeric) %>%
mutate(year = as.factor(year)) %>%
select(flipper_length_mm, body_mass_g, year) %>%
head()mutate() cambia o crea una sola variable en el dataframe, mientras que mutate_at() cambia múltiples variables a otro formato simultáneamente, siendo eficiente para transformaciones específicas en columnas seleccionadas del dataframe.
Recodificar etiquetas de variables: recode()
La función recode() permite asignar nuevos valores a elementos específicos según condiciones establecidas. Por ejemplo, es útil para cambiar valores de una variable categórica o agrupar valores numéricos en categorías predefinidas. Esta función ofrece una forma conveniente de realizar estas recodificaciones en los datos de manera eficiente.
Para este caso, se cambiarán las etiquetas de una variable categórica. Se trabajará con la variable sex, donde la etiqueta female será modificada a Hembra, y la etiqueta male será ajustada a Macho.6
6 En caso de no requerir que la variable sea factor, se puede usar la función recode() con la misma lógica.
penguins %>%
mutate(sex_rec = recode_factor(sex, female = "Hembra",
male = "Macho")) %>%
select(sex, sex_rec) %>%
head()Para explorar más sobre las capacidades de la función mutate(), puedes consultar el siguiente enlace: https://dplyr.tidyverse.org/reference/mutate.html
Agrupar el marco de datos: group_by()
La función group_by() es crucial para dividir un marco de datos en grupos según variables específicas. Al utilizarla, se pueden llevar a cabo operaciones de resumen o cálculos agregados en cada grupo por separado mediante la función summarize(); esta función se desarrolla más adelante. Esto proporciona un análisis más detallado y específico, permitiendo identificar patrones y tendencias únicas en cada grupo de datos y facilitando una comprensión más profunda de la información contenida en el marco de datos.
penguins %>%
group_by(species, sex) %>%
filter(body_mass_g <= 4050) %>%
arrange(year) %>%
head()Resumir datos: summarise()
summarise() de dplyr es una función esencial para calcular estadísticas resumidas y métricas agregadas en un data frame. Permite obtener información clave de los datos, como sumas, promedios o desviaciones estándar, entre otras, ya sea para todo el conjunto o agrupando por categorías específicas. Es una herramienta valiosa para obtener una visión rápida y concisa de los datos antes de análisis más detallados. Generalmente, summarise() se utiliza en conjunto con la función de agrupamiento group_by() mencionada atrás, la cual agrupa el marco muestral según una o varias variables específicas.
En situaciones en las que necesiten utilizar los resultados de tablas resumen, como la que se muestra a continuación, es conveniente crear una nueva variable que permita acceder a esos datos de manera más eficiente y sin alterar el marco de datos original. Al hacerlo, se evita realizar cálculos repetidos y se garantiza un acceso más ágil a los datos agregados. De esta forma, se puede simplificar el flujo de trabajo y se facilita la exploración y análisis de los datos sin afectar la integridad de la información original.
Ejemplos
Para ejemplificar esta función, se generó una tabla resumen que muestra la información segregada por el tipo de especie de los pingüinos y la isla a la que pertenecen. En la tabla se incluye el total de pingüinos, la media de la longitud de las aletas, el peso promedio y la desviación estándar del peso.
# Generar la tabla resumen:
df = penguins %>%
group_by(species, island) %>%
summarise(total = n(),
media_long_aleta = mean(flipper_length_mm, na.rm = T),
media_peso = mean(body_mass_g, na.rm = T),
sd_peso = sd(body_mass_g, na.rm = T))# Mostrar la tabla resumen:
dfOtro ejemplo que hace uso de esta función es el siguiente. En este ejercicio se agrupó el marco de datos por el tipo especie de los pingüinos para realizar una tabla resumen que tuviera la información sobre la media y la desviación estándar de la longitud del pico y la profundidad de este. Vea que se usó la función across() para aplicar dichos cálculos a todas las columnas seleccionadas.
penguins %>%
group_by(species) %>%
summarise(across(starts_with("bill_"),
list(media = ~mean(., na.rm = T),
desv = ~var(., na.rm = T))))Funciones extra
Seleccionar filas: slice()
La función slice() permite a los usuarios seleccionar filas individuales mediante su índice o incluso extraer un rango de filas utilizando intervalos. Esta funcionalidad resulta especialmente valiosa cuando se requiere visualizar, analizar o procesar únicamente un subconjunto específico de observaciones relevantes en el conjunto de datos.7
7 Esta función es muy útil para el curso de XS-3110 Principios y Técnicas de Muestreo que imparte la docente PhD. María Fernanda Alvarado Leitón.
Ejemplo
Primero, se generó un vector de diez números aleatorios (sin reemplazo) que se utilizarán como números de identificación para seleccionar una submuestra del marco muestral (base de pingüinos). Luego, se crea una nueva variable que contendrá la base de datos con los valores de identificación seleccionados en la variable id_sample utilizando la función slice().
# Filas a seleccionar de forma aleatoria:
id_sample = sample(1:nrow(penguins), size = 10, replace = F) ; id_sample [1] 9 83 303 319 172 329 201 50 63 109# Concretar la selección en el marco muestral:
df_sample = penguins %>%
slice(id_sample) %>%
select(1:2, 9) # Base de datos con los ID seleccionados:
df_sampleUnir datos: funciones join()
La familia de funciones join() permite a los usuarios combinar datos de diferentes tablas según variables comunes. Las funciones principales, como inner_join(), left_join(), right_join() y full_join(), ofrecen diferentes tipos de uniones entre tablas. Por ejemplo, inner_join() conserva solo las filas que tienen coincidencias en ambas tablas, left_join() mantiene todas las filas de la tabla izquierda y agrega las coincidencias de la tabla derecha, right_join() hace lo contrario y full_join() conserva todas las filas de ambas tablas, agregando valores faltantes cuando no hay coincidencias.
Estas funciones resultan valiosas al combinar datos de distintas fuentes, permitiendo crear conjuntos de datos más completos y enriquecidos para análisis, visualizaciones o modelado. Al utilizar join(), los usuarios pueden unir tablas según criterios específicos, brindando flexibilidad para trabajar con marcos de datos complejos y desordenados.
En este manual se recomienda ver los siguientes dos vídeos en la plataforma de YouTube que explican y presentan de forma más concreta el uso de estas funciones de la familia join() mencionadas atrás.
- Video 1 - “dplyr:Joins()”: https://www.youtube.com/watch?v=4-DjmCnVRUk
- Video 2 - “Join Data with dplyr in R (6 Examples) | inner, left, righ, full, semi & anti”: https://www.youtube.com/watch?v=Yg-pNqzDuN4
Cheat Sheet
El Cheat Sheet de dplyr es una guía de referencia rápida que proporciona una visión general de las principales funciones y operaciones de manipulación de datos disponibles en la librería dplyr de R.
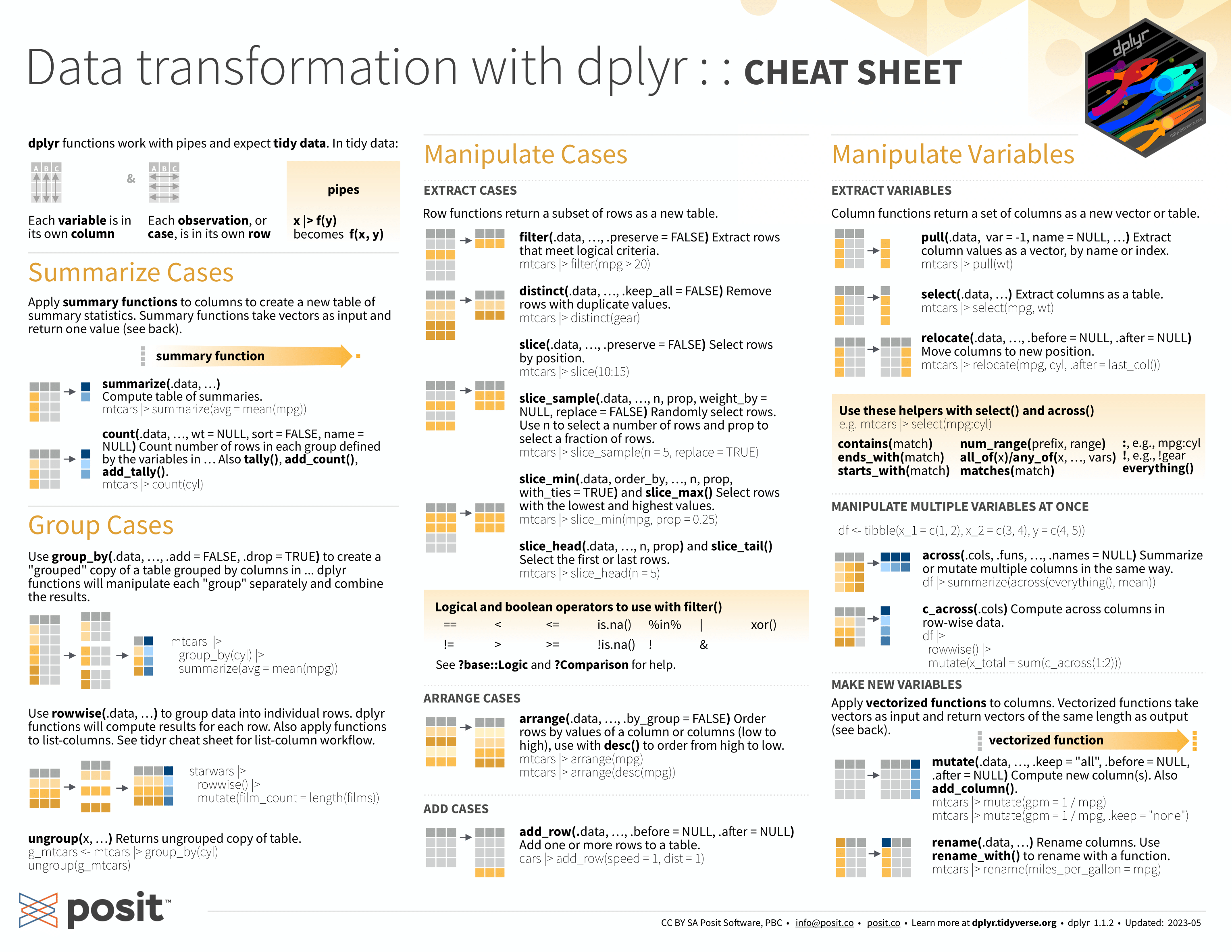
dplyr.
dplyr.Referencias
Bache, Stefan Milton, y Hadley Wickham. 2022. magrittr: A Forward-Pipe Operator for R. https://CRAN.R-project.org/package=magrittr.
Grolemund, Garrett, y Hadley Wickham. 2011. «Dates and Times Made Easy with lubridate». Journal of Statistical Software 40 (3): 1-25. https://www.jstatsoft.org/v40/i03/.
Horst, Allison Marie, Alison Presmanes Hill, y Kristen B Gorman. 2020. palmerpenguins: Palmer Archipelago (Antarctica) penguin data. https://doi.org/10.5281/zenodo.3960218.
Wickham, Hadley. 2016. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. https://ggplot2.tidyverse.org.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. «Welcome to the tidyverse». Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Wickham, Hadley, Jim Hester, y Jennifer Bryan. 2023. readr: Read Rectangular Text Data. https://CRAN.R-project.org/package=readr.
Wickham, Hadley, Davis Vaughan, y Maximilian Girlich. 2023. tidyr: Tidy Messy Data. https://CRAN.R-project.org/package=tidyr.
Cómo citar
BibTeX
@online{daniel rodríguez cruz2023,
author = {Daniel Rodríguez Cruz, Iván},
title = {Introducción a dplyr},
date = {2023-07-22},
url = {https://ivanrodc.quarto.pub/idcr_blog_stat/articulos_textos/intro_dplyr/intro_dplyr.html},
langid = {es}
}
Por favor, cita este trabajo como:
Daniel Rodríguez Cruz, Iván. 2023. “Introducción a dplyr.”
July 22, 2023. https://ivanrodc.quarto.pub/idcr_blog_stat/articulos_textos/intro_dplyr/intro_dplyr.html.